图的构建
GraphX的Graph对象是用户操作图的入口。前面的章节我们介绍过,它包含了边(edges)、顶点(vertices)以及triplets三部分,并且这三部分都包含相应的属性,可以携带额外的信息。
1 构建图的方法
构建图的入口方法有两种,分别是根据边构建和根据边的两个顶点构建。
- 根据边构建图(Graph.fromEdges)
def fromEdges[VD: ClassTag, ED: ClassTag](
edges: RDD[Edge[ED]],
defaultValue: VD,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, ED] = {
GraphImpl(edges, defaultValue, edgeStorageLevel, vertexStorageLevel)
}
- 根据边的两个顶点数据构建(Graph.fromEdgeTuples)
def fromEdgeTuples[VD: ClassTag](
rawEdges: RDD[(VertexId, VertexId)],
defaultValue: VD,
uniqueEdges: Option[PartitionStrategy] = None,
edgeStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY,
vertexStorageLevel: StorageLevel = StorageLevel.MEMORY_ONLY): Graph[VD, Int] =
{
val edges = rawEdges.map(p => Edge(p._1, p._2, 1))
val graph = GraphImpl(edges, defaultValue, edgeStorageLevel, vertexStorageLevel)
uniqueEdges match {
case Some(p) => graph.partitionBy(p).groupEdges((a, b) => a + b)
case None => graph
}
}
从上面的代码我们知道,不管是根据边构建图还是根据边的两个顶点数据构建,最终都是使用GraphImpl来构建的,即调用了GraphImpl的apply方法。
2 构建图的过程
构建图的过程很简单,分为三步,它们分别是构建边EdgeRDD、构建顶点VertexRDD、生成Graph对象。下面分别介绍这三个步骤。
2.1 构建边EdgeRDD
从源代码看构建边EdgeRDD也分为三步,下图的例子详细说明了这些步骤。
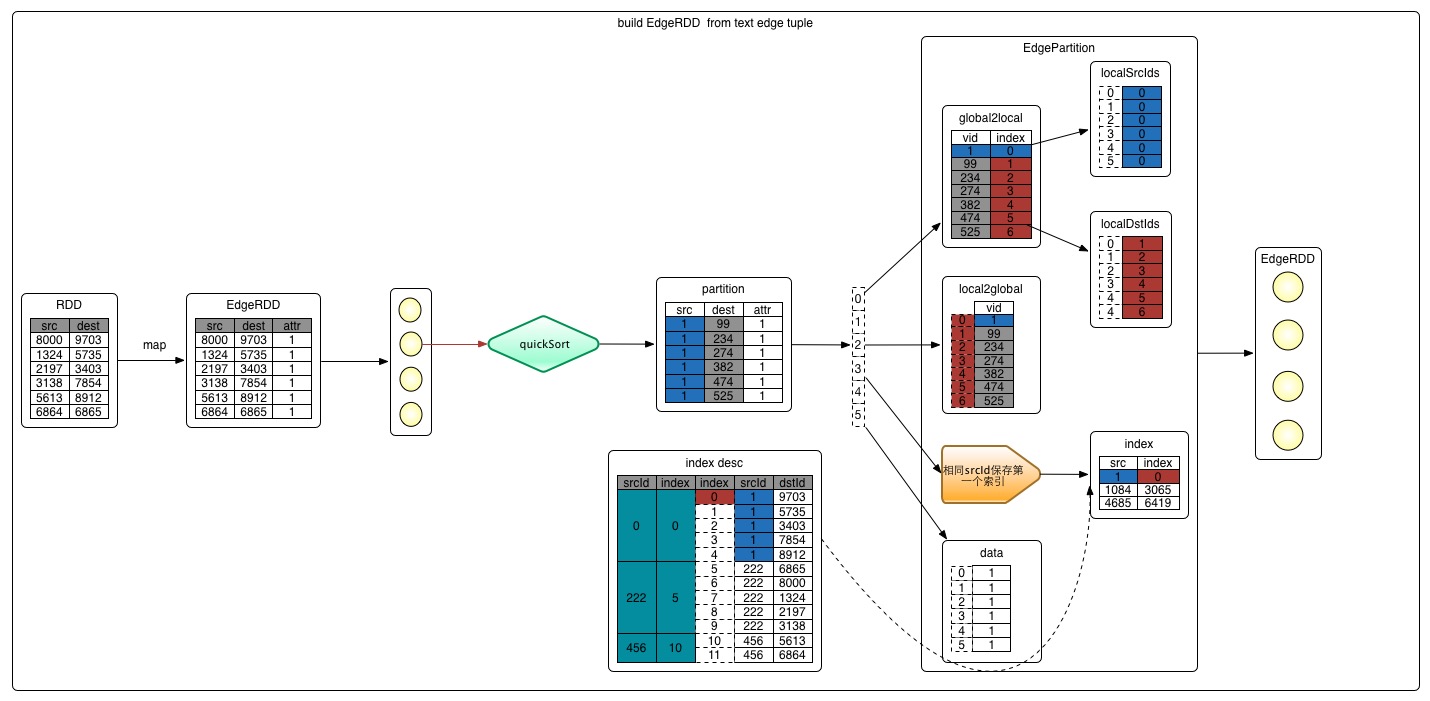
- 1 从文件中加载信息,转换成
tuple的形式,即(srcId, dstId)
val rawEdgesRdd: RDD[(Long, Long)] =
sc.textFile(input).filter(s => s != "0,0").repartition(partitionNum).map {
case line =>
val ss = line.split(",")
val src = ss(0).toLong
val dst = ss(1).toLong
if (src < dst)
(src, dst)
else
(dst, src)
}.distinct()
- 2 入口,调用
Graph.fromEdgeTuples(rawEdgesRdd)
源数据为分割的两个点ID,把源数据映射成Edge(srcId, dstId, attr)对象, attr默认为1。这样元数据就构建成了RDD[Edge[ED]],如下面的代码
val edges = rawEdges.map(p => Edge(p._1, p._2, 1))
- 3 将
RDD[Edge[ED]]进一步转化成EdgeRDDImpl[ED, VD]
第二步构建完RDD[Edge[ED]]之后,GraphX通过调用GraphImpl的apply方法来构建Graph。
val graph = GraphImpl(edges, defaultValue, edgeStorageLevel, vertexStorageLevel)
def apply[VD: ClassTag, ED: ClassTag](
edges: RDD[Edge[ED]],
defaultVertexAttr: VD,
edgeStorageLevel: StorageLevel,
vertexStorageLevel: StorageLevel): GraphImpl[VD, ED] = {
fromEdgeRDD(EdgeRDD.fromEdges(edges), defaultVertexAttr, edgeStorageLevel, vertexStorageLevel)
}
在apply调用fromEdgeRDD之前,代码会调用EdgeRDD.fromEdges(edges)将RDD[Edge[ED]]转化成EdgeRDDImpl[ED, VD]。
def fromEdges[ED: ClassTag, VD: ClassTag](edges: RDD[Edge[ED]]): EdgeRDDImpl[ED, VD] = {
val edgePartitions = edges.mapPartitionsWithIndex { (pid, iter) =>
val builder = new EdgePartitionBuilder[ED, VD]
iter.foreach { e =>
builder.add(e.srcId, e.dstId, e.attr)
}
Iterator((pid, builder.toEdgePartition))
}
EdgeRDD.fromEdgePartitions(edgePartitions)
}
程序遍历RDD[Edge[ED]]的每个分区,并调用builder.toEdgePartition对分区内的边作相应的处理。
def toEdgePartition: EdgePartition[ED, VD] = {
val edgeArray = edges.trim().array
new Sorter(Edge.edgeArraySortDataFormat[ED])
.sort(edgeArray, 0, edgeArray.length, Edge.lexicographicOrdering)
val localSrcIds = new Array[Int](edgeArray.size)
val localDstIds = new Array[Int](edgeArray.size)
val data = new Array[ED](edgeArray.size)
val index = new GraphXPrimitiveKeyOpenHashMap[VertexId, Int]
val global2local = new GraphXPrimitiveKeyOpenHashMap[VertexId, Int]
val local2global = new PrimitiveVector[VertexId]
var vertexAttrs = Array.empty[VD]
//采用列式存储的方式,节省了空间
if (edgeArray.length > 0) {
index.update(edgeArray(0).srcId, 0)
var currSrcId: VertexId = edgeArray(0).srcId
var currLocalId = -1
var i = 0
while (i < edgeArray.size) {
val srcId = edgeArray(i).srcId
val dstId = edgeArray(i).dstId
localSrcIds(i) = global2local.changeValue(srcId,
{ currLocalId += 1; local2global += srcId; currLocalId }, identity)
localDstIds(i) = global2local.changeValue(dstId,
{ currLocalId += 1; local2global += dstId; currLocalId }, identity)
data(i) = edgeArray(i).attr
//相同顶点srcId中第一个出现的srcId与其下标
if (srcId != currSrcId) {
currSrcId = srcId
index.update(currSrcId, i)
}
i += 1
}
vertexAttrs = new Array[VD](currLocalId + 1)
}
new EdgePartition(
localSrcIds, localDstIds, data, index, global2local, local2global.trim().array, vertexAttrs,
None)
}
toEdgePartition的第一步就是对边进行排序。
按照srcId从小到大排序。排序是为了遍历时顺序访问,加快访问速度。采用数组而不是Map,是因为数组是连续的内存单元,具有原子性,避免了Map的hash问题,访问速度快。
toEdgePartition的第二步就是填充localSrcIds,localDstIds, data, index, global2local, local2global, vertexAttrs。
数组localSrcIds,localDstIds中保存的是通过global2local.changeValue(srcId/dstId)转换而成的分区本地索引。可以通过localSrcIds、localDstIds数组中保存的索引位从local2global中查到具体的VertexId。
global2local是一个简单的,key值非负的快速hash map:GraphXPrimitiveKeyOpenHashMap, 保存vertextId和本地索引的映射关系。global2local中包含当前partition所有srcId、dstId与本地索引的映射关系。
data就是当前分区的attr属性数组。
我们知道相同的srcId可能对应不同的dstId。按照srcId排序之后,相同的srcId会出现多行,如上图中的index desc部分。index中记录的是相同srcId中第一个出现的srcId与其下标。
local2global记录的是所有的VertexId信息的数组。形如:srcId,dstId,srcId,dstId,srcId,dstId,srcId,dstId。其中会包含相同的srcId。即:当前分区所有vertextId的顺序实际值。
我们可以通过根据本地下标取VertexId,也可以根据VertexId取本地下标,取相应的属性。
// 根据本地下标取VertexId
localSrcIds/localDstIds -> index -> local2global -> VertexId
// 根据VertexId取本地下标,取属性
VertexId -> global2local -> index -> data -> attr object
2.2 构建顶点VertexRDD
紧接着上面构建边RDD的代码,我们看看方法fromEdgeRDD的实现。
private def fromEdgeRDD[VD: ClassTag, ED: ClassTag](
edges: EdgeRDDImpl[ED, VD],
defaultVertexAttr: VD,
edgeStorageLevel: StorageLevel,
vertexStorageLevel: StorageLevel): GraphImpl[VD, ED] = {
val edgesCached = edges.withTargetStorageLevel(edgeStorageLevel).cache()
val vertices = VertexRDD.fromEdges(edgesCached, edgesCached.partitions.size, defaultVertexAttr)
.withTargetStorageLevel(vertexStorageLevel)
fromExistingRDDs(vertices, edgesCached)
}
从上面的代码我们可以知道,GraphX使用VertexRDD.fromEdges构建顶点VertexRDD,当然我们把边RDD作为参数传入。
def fromEdges[VD: ClassTag](
edges: EdgeRDD[_], numPartitions: Int, defaultVal: VD): VertexRDD[VD] = {
//1 创建路由表
val routingTables = createRoutingTables(edges, new HashPartitioner(numPartitions))
//2 根据路由表生成分区对象vertexPartitions
val vertexPartitions = routingTables.mapPartitions({ routingTableIter =>
val routingTable =
if (routingTableIter.hasNext) routingTableIter.next() else RoutingTablePartition.empty
Iterator(ShippableVertexPartition(Iterator.empty, routingTable, defaultVal))
}, preservesPartitioning = true)
//3 创建VertexRDDImpl对象
new VertexRDDImpl(vertexPartitions)
}
构建顶点VertexRDD的过程分为三步,如上代码中的注释。它的构建过程如下图所示:
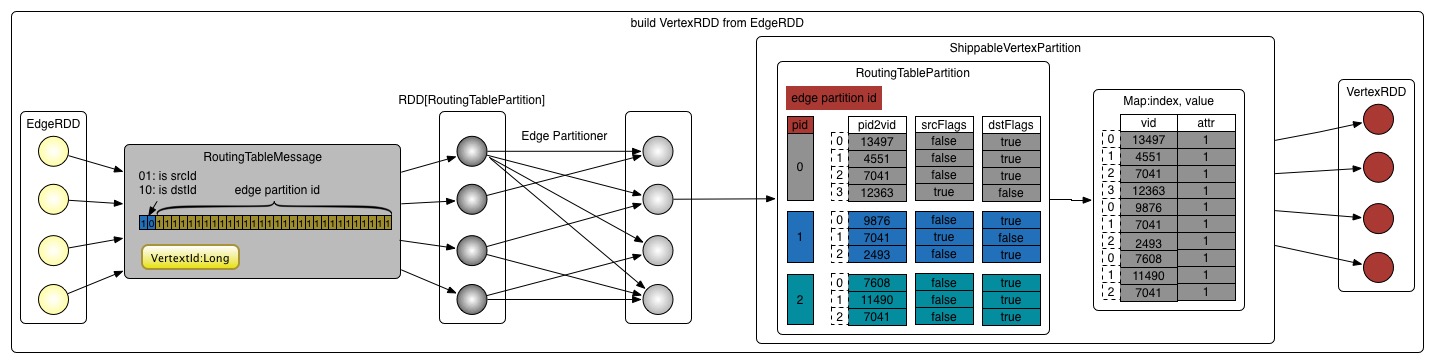
- 1 创建路由表
为了能通过点找到边,每个点需要保存点到边的信息,这些信息保存在RoutingTablePartition中。
private[graphx] def createRoutingTables(
edges: EdgeRDD[_], vertexPartitioner: Partitioner): RDD[RoutingTablePartition] = {
// 将edge partition中的数据转换成RoutingTableMessage类型,
val vid2pid = edges.partitionsRDD.mapPartitions(_.flatMap(
Function.tupled(RoutingTablePartition.edgePartitionToMsgs)))
}
上述程序首先将边分区中的数据转换成RoutingTableMessage类型,即tuple(VertexId,Int)类型。
def edgePartitionToMsgs(pid: PartitionID, edgePartition: EdgePartition[_, _])
: Iterator[RoutingTableMessage] = {
val map = new GraphXPrimitiveKeyOpenHashMap[VertexId, Byte]
edgePartition.iterator.foreach { e =>
map.changeValue(e.srcId, 0x1, (b: Byte) => (b | 0x1).toByte)
map.changeValue(e.dstId, 0x2, (b: Byte) => (b | 0x2).toByte)
}
map.iterator.map { vidAndPosition =>
val vid = vidAndPosition._1
val position = vidAndPosition._2
toMessage(vid, pid, position)
}
}
//`30-0`比特位表示边分区`ID`,`32-31`比特位表示标志位
private def toMessage(vid: VertexId, pid: PartitionID, position: Byte): RoutingTableMessage = {
val positionUpper2 = position << 30
val pidLower30 = pid & 0x3FFFFFFF
(vid, positionUpper2 | pidLower30)
}
根据代码,我们可以知道程序使用int的32-31比特位表示标志位,即01: isSrcId ,10: isDstId。30-0比特位表示边分区ID。这样做可以节省内存。
RoutingTableMessage表达的信息是:顶点id和它相关联的边的分区id是放在一起的,所以任何时候,我们都可以通过RoutingTableMessage找到顶点关联的边。
- 2 根据路由表生成分区对象
private[graphx] def createRoutingTables(
edges: EdgeRDD[_], vertexPartitioner: Partitioner): RDD[RoutingTablePartition] = {
// 将edge partition中的数据转换成RoutingTableMessage类型,
val numEdgePartitions = edges.partitions.size
vid2pid.partitionBy(vertexPartitioner).mapPartitions(
iter => Iterator(RoutingTablePartition.fromMsgs(numEdgePartitions, iter)),
preservesPartitioning = true)
}
我们将第1步生成的vid2pid按照HashPartitioner重新分区。我们看看RoutingTablePartition.fromMsgs方法。
def fromMsgs(numEdgePartitions: Int, iter: Iterator[RoutingTableMessage])
: RoutingTablePartition = {
val pid2vid = Array.fill(numEdgePartitions)(new PrimitiveVector[VertexId])
val srcFlags = Array.fill(numEdgePartitions)(new PrimitiveVector[Boolean])
val dstFlags = Array.fill(numEdgePartitions)(new PrimitiveVector[Boolean])
for (msg <- iter) {
val vid = vidFromMessage(msg)
val pid = pidFromMessage(msg)
val position = positionFromMessage(msg)
pid2vid(pid) += vid
srcFlags(pid) += (position & 0x1) != 0
dstFlags(pid) += (position & 0x2) != 0
}
new RoutingTablePartition(pid2vid.zipWithIndex.map {
case (vids, pid) => (vids.trim().array, toBitSet(srcFlags(pid)), toBitSet(dstFlags(pid)))
})
}
该方法从RoutingTableMessage获取数据,将vid, 边pid, isSrcId/isDstId重新封装到pid2vid,srcFlags,dstFlags这三个数据结构中。它们表示当前顶点分区中的点在边分区的分布。
想象一下,重新分区后,新分区中的点可能来自于不同的边分区,所以一个点要找到边,就需要先确定边的分区号pid, 然后在确定的边分区中确定是srcId还是dstId, 这样就找到了边。
新分区中保存vids.trim().array, toBitSet(srcFlags(pid)), toBitSet(dstFlags(pid))这样的记录。这里转换为toBitSet保存是为了节省空间。
根据上文生成的routingTables,重新封装路由表里的数据结构为ShippableVertexPartition。ShippableVertexPartition会合并相同重复点的属性attr对象,补全缺失的attr对象。
def apply[VD: ClassTag](
iter: Iterator[(VertexId, VD)], routingTable: RoutingTablePartition, defaultVal: VD,
mergeFunc: (VD, VD) => VD): ShippableVertexPartition[VD] = {
val map = new GraphXPrimitiveKeyOpenHashMap[VertexId, VD]
// 合并顶点
iter.foreach { pair =>
map.setMerge(pair._1, pair._2, mergeFunc)
}
// 不全缺失的属性值
routingTable.iterator.foreach { vid =>
map.changeValue(vid, defaultVal, identity)
}
new ShippableVertexPartition(map.keySet, map._values, map.keySet.getBitSet, routingTable)
}
//ShippableVertexPartition定义
ShippableVertexPartition[VD: ClassTag](
val index: VertexIdToIndexMap,
val values: Array[VD],
val mask: BitSet,
val routingTable: RoutingTablePartition)
map就是映射vertexId->attr,index就是顶点集合,values就是顶点集对应的属性集,mask指顶点集的BitSet。
2.3 生成Graph对象
使用上述构建的edgeRDD和vertexRDD,使用 new GraphImpl(vertices, new ReplicatedVertexView(edges.asInstanceOf[EdgeRDDImpl[ED, VD]])) 就可以生成Graph对象。
ReplicatedVertexView是点和边的视图,用来管理运送(shipping)顶点属性到EdgeRDD的分区。当顶点属性改变时,我们需要运送它们到边分区来更新保存在边分区的顶点属性。
注意,在ReplicatedVertexView中不要保存一个对边的引用,因为在属性运送等级升级后,这个引用可能会发生改变。
class ReplicatedVertexView[VD: ClassTag, ED: ClassTag](
var edges: EdgeRDDImpl[ED, VD],
var hasSrcId: Boolean = false,
var hasDstId: Boolean = false)
3 参考文献
【2】spark源码