river-jdbc
安装
./bin/plugin --install jdbc --url http://xbib.org/repository/org/xbib/elasticsearch/plugin/elasticsearch-river-jdbc/1.4.0.8/elasticsearch-river-jdbc-1.4.0.8-plugin.zip
文档
两种方式:river或者feeder
该插件能够以“pull模式”执行river和以“push模式”执行feeder。在feeder模式下插件运行在不同的JVM中,可以连接到远程的Elasticsearch集群。
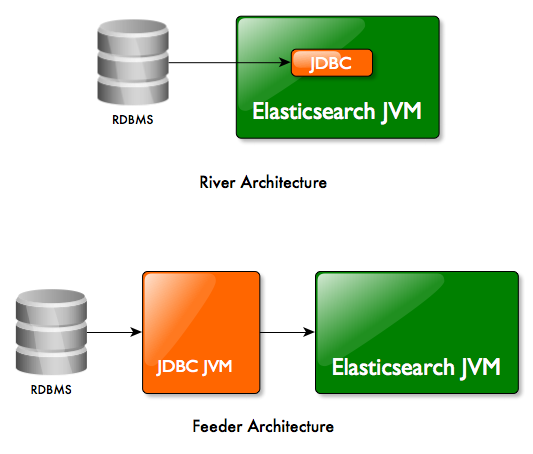
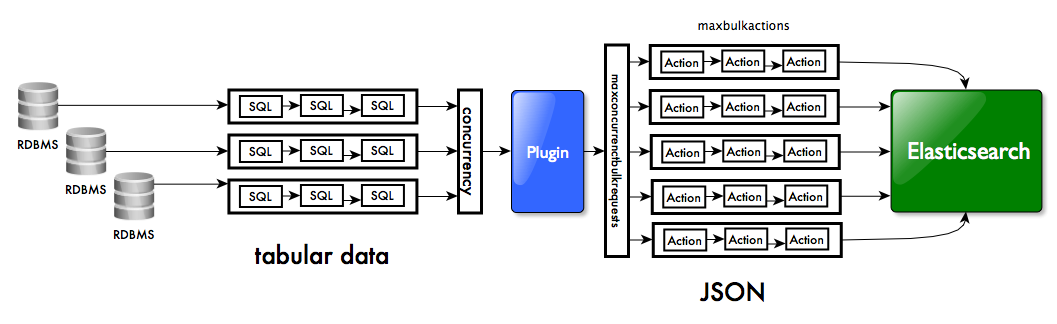
该插件可以从不同的关系数据库源并行的获取数据。当索引到elasticsearch中时,多线程bulk模式确保了高吞吐。
安装运行river
#安装elasticsearch
curl -OL https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.zip
cd $ES_HOME
unzip path/to/elasticsearch-1.4.2.zip
#安装JDBC插件
./bin/plugin --install jdbc --url http://xbib.org/repository/org/xbib/elasticsearch/plugin/elasticsearch-river-jdbc/1.4.0.6/elasticsearch-river-jdbc-1.4.0.6-plugin.zip
#下载mysql driver
curl -o mysql-connector-java-5.1.33.zip -L 'http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.33.zip/from/http://cdn.mysql.com/'
cp mysql-connector-java-5.1.33-bin.jar $ES_HOME/plugins/jdbc/ chmod 644 $ES_HOME/plugins/jdbc/*
#启动elasticsearch
./bin/elasticsearch
#停止river
curl -XDELETE 'localhost:9200/_river/my_jdbc_river/'
JDBC插件参数
JDBC插件一般的格式如下:
curl -XPUT 'localhost:9200/_river/<rivername>/_meta' -d '{
<river parameters>
"type" : "jdbc",
"jdbc" : {
<river definition>
}
}'
例如
curl -XPUT 'localhost:9200/_river/my_jdbc_river/_meta' -d '{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://localhost:3306/test",
"user" : "",
"password" : "",
"sql" : "select * from orders",
"index" : "myindex",
"type" : "mytype",
...
}
}'
如果一个数组传递给jdbc字段,多个river源也是可以的。
curl -XPUT 'localhost:9200/_river/my_jdbc_river/_meta' -d '{
<river parameters>
"type" : "jdbc",
"jdbc" : [ {
<river definition 1>
}, {
<river definition 2>
} ]
}'
可以通过concurrency参数并行控制多个river源
curl -XPUT 'localhost:9200/_river/my_jdbc_river/_meta' -d '{
<river parameters>
"concurrency" : 2,
"type" : "jdbc",
"jdbc" : [ {
<river definition 1>
}, {
<river definition 2>
} ]
}'
jdbc块外部的参数
strategy - JDBC插件的策略。当前的实现有simple和column。
schedule - a single or a list of cron expressions for scheduled execution
threadpoolsize -scheduled executions的线程池大小
interval - 两个river启动的延迟时间
max_bulk_actions - 每个bulk索引请求提交的长度(默认是1000)
max_concurrrent_bulk_requests - bulk请求的并行数量(默认是2*cpu core)
max_bulk_volume - 一个bulk请求的最大容量(默认是10m)
max_request_wait - 一个bulk请求最大的等待时间(默认是60s)
flush_interval - flushing索引文档到bulk action的间隔时间
jdbc块内部的参数
url - the JDBC driver URL
user - the JDBC database user
password - the JDBC database password
sql - SQL语句。既可以是一个字符串也可以是一个列表。
"sql" : [
{
"statement" : "select ... from ... where a = ?, b = ?, c = ?",
"parameter" : [ "value for a", "value for b", "value for c" ]
},
{
"statement" : "insert into ... where a = ?, b = ?, c = ?",
"parameter" : [ "value for a", "value for b", "value for c" ],
"write" : "true"
},
{
"statement" : ...
}
]
sql.statement - the SQL statement
sql.write - 如果为true,SQL语句解释为一个insert/update语句,这个语句写权限。默认为false
sql.callable - 如果为true,SQL语句解释为一个CallableStatement用于保存存储过程。默认为false
sql.parameter - 绑定参数到SQL语句。可以用到一些指定的值
- $now - the current timestamp
- $job - a job counter
- $count - last number of rows merged
- $river.name - the river name
- $last.sql.start - a timestamp value for the time when the last SQL statement started
- $last.sql.end - a timestamp value for the time when the last SQL statement ended
- $last.sql.sequence.start - a timestamp value for the time when the last SQL sequence started
- $last.sql.sequence.end - a timestamp value for the time when the last SQL sequence ended
- $river.state.started - the timestamp of river start (from river state)
- $river.state.timestamp - last timestamp of river activity (from river state)
- $river.state.counter - counter from river state, counts the numbers of runs
locale - the default locale (used for parsing numerical values, floating point character. Recommended values is "en_US")
timezone - the timezone for JDBC setTimestamp() calls when binding parameters with timestamp values
rounding - rounding mode for parsing numeric values. Possible values "ceiling", "down", "floor", "halfdown", "halfeven", "halfup", "unnecessary", "up"
scale - the precision of parsing numeric values
autocommit - true if each statement should be automatically executed. Default is false
fetchsize - the fetchsize for large result sets, most drivers use this to control the amount of rows in the buffer while iterating through the result set
max_rows - limit the number of rows fetches by a statement, the rest of the rows is ignored
max_retries - the number of retries to (re)connect to a database
max_retries_wait - a time value for the time that should be waited between retries. Default is "30s"
resultset_type - the JDBC result set type, can be TYPE_FORWARD_ONLY, TYPE_SCROLL_SENSITIVE, TYPE_SCROLL_INSENSITIVE. Default is TYPE_FORWARD_ONLY
resultset_concurrency - the JDBC result set concurrency, can be CONCUR_READ_ONLY, CONCUR_UPDATABLE. Default is CONCUR_UPDATABLE
ignore_null_values - if NULL values should be ignored when constructing JSON documents. Default is false
prepare_database_metadata - if the driver metadata should be prepared as parameters for acccess by the river. Default is false
prepare_resultset_metadata - if the result set metadata should be prepared as parameters for acccess by the river. Default is false
column_name_map - a map of aliases that should be used as a replacement for column names of the database. Useful for Oracle 30 char column name limit. Default is null
query_timeout - a second value for how long an SQL statement is allowed to be executed before it is considered as lost. Default is 1800
connection_properties - a map for the connection properties for driver connection creation. Default is null
index - the Elasticsearch index used for indexing
type - the Elasticsearch type of the index used for indexing
index_settings - optional settings for the Elasticsearch index
type_mapping - optional mapping for the Elasticsearch index type
默认的参数设置
{
"strategy" : "simple",
"schedule" : null,
"interval" : 0L,
"threadpoolsize" : 4,
"max_bulk_actions" : 10000,
"max_concurrent_bulk_requests" : 2 * available CPU cores,
"max_bulk_volume" : "10m",
"max_request_wait" : "60s",
"flush_interval" : "5s",
"jdbc" : {
"url" : null,
"user" : null,
"password" : null,
"sql" : null,
"locale" : Locale.getDefault().toLanguageTag(),
"timezone" : TimeZone.getDefault(),
"rounding" : null,
"scale" : 2,
"autocommit" : false,
"fetchsize" : 10, /* MySQL: Integer.MIN */
"max_rows" : 0,
"max_retries" : 3,
"max_retries_wait" : "30s",
"resultset_type" : "TYPE_FORWARD_ONLY",
"resultset_concurreny" : "CONCUR_UPDATABLE",
"ignore_null_values" : false,
"prepare_database_metadata" : false,
"prepare_resultset_metadata" : false,
"column_name_map" : null,
"query_timeout" : 1800,
"connection_properties" : null,
"index" : "jdbc",
"type" : "jdbc",
"index_settings" : null,
"type_mapping" : null,
}
}
结构化对象
SQL查询的一个优势是连接操作。从许多表获得数据形成新的元组。
curl -XPUT 'localhost:9200/_river/my_jdbc_river/_meta' -d '{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://localhost:3306/test",
"user" : "",
"password" : "",
"sql" : "select \"relations\" as \"_index\", orders.customer as \"_id\", orders.customer as \"contact.customer\", employees.name as \"contact.employee\" from orders left join employees on employees.department = orders.department"
}
}'
sql结构是
mysql> select "relations" as "_index", orders.customer as "_id", orders.customer as "contact.customer", employees.name as "contact.employee" from orders left join employees on employees.department = orders.department;
+-----------+-------+------------------+------------------+
| _index | _id | contact.customer | contact.employee |
+-----------+-------+------------------+------------------+
| relations | Big | Big | Smith |
| relations | Large | Large | Müller |
| relations | Large | Large | Meier |
| relations | Large | Large | Schulze |
| relations | Huge | Huge | Müller |
| relations | Huge | Huge | Meier |
| relations | Huge | Huge | Schulze |
| relations | Good | Good | Müller |
| relations | Good | Good | Meier |
| relations | Good | Good | Schulze |
| relations | Bad | Bad | Jones |
+-----------+-------+------------------+------------------+
11 rows in set (0.00 sec)
得到的JSON对象为
index=relations id=Big {"contact":{"employee":"Smith","customer":"Big"}}
index=relations id=Large {"contact":{"employee":["Müller","Meier","Schulze"],"customer":"Large"}}
index=relations id=Huge {"contact":{"employee":["Müller","Meier","Schulze"],"customer":"Huge"}}
index=relations id=Good {"contact":{"employee":["Müller","Meier","Schulze"],"customer":"Good"}}
index=relations id=Bad {"contact":{"employee":"Jones","customer":"Bad"}}
怎样获取一个表
它dump一个表到Elasticsearch中。如果没有给定_id列,IDs将会自动生成。
curl -XPUT 'localhost:9200/_river/my_jdbc_river/_meta' -d '{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://localhost:3306/test",
"user" : "",
"password" : "",
"sql" : "select * from orders"
}
}'
结果是:
id=<random> {"product":"Apples","created":null,"department":"American Fruits","quantity":1,"customer":"Big"}
id=<random> {"product":"Bananas","created":null,"department":"German Fruits","quantity":1,"customer":"Large"}
id=<random> {"product":"Oranges","created":null,"department":"German Fruits","quantity":2,"customer":"Huge"}
id=<random> {"product":"Apples","created":1338501600000,"department":"German Fruits","quantity":2,"customer":"Good"}
id=<random> {"product":"Oranges","created":1338501600000,"department":"English Fruits","quantity":3,"customer":"Bad"}
怎样获得增量的数据
推荐使用时间戳来同步。下面的例子获取最后一次river运行之后添加的所有产品行。
{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://localhost:3306/test",
"user" : "",
"password" : "",
"sql" : [
{
"statement" : "select * from \"products\" where \"mytimestamp\" > ?",
"parameter" : [ "$river.state.last_active_begin" ]
}
],
"index" : "my_jdbc_river_index",
"type" : "my_jdbc_river_type"
}
}